1)文字データを声に変える
最近はパソコンやスマートフォンでもすでに文字データを読み上げるよう機能が備わってきています。このような機能を音声合成とか、TextToSpeech等と言っています。今回は、私たちもAIが返事をした内容を発声させます。
今回利用するライブラリーはOpenJTalkです。ローカル環境で稼働する機能となります。
2)ライブラリをインストールします。
[ライブラリー]
sudo apt-get install open-jtalk open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001
3)下記を順番に入力し音声データをインストールします。
[音声データ]
wget https://sourceforge.net/projects/mmdagent/files/MMDAgent_Example/MMDAgent_Example-1.6/MMDAgent_Example-1.6.zip/download -O MMDAgent_Example-1.6.zip
unzip MMDAgent_Example-1.6.zip MMDAgent_Example-1.6/Voice/*
sudo cp -r MMDAgent_Example-1.6/Voice/mei/ /usr/share/hts-voice
4)プログラムを作成します。[TextToSpeech_Jtalk.py]

5)デバイス番号を確認しプログラムのデバイス番号の指定が同じになっているか確認します。デバイス番号を確認する方法は下記の通りです。
aplay -l
USBスピーカーのカード番号を確認します。カード番号が0番になっている事がわかります。
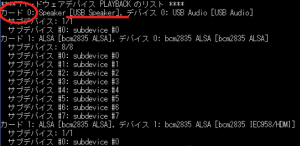
プログラムのマーカー部分が1番になっているのでこの部分を0番に書き替えしないとエラーになってしまいます。上記の方法で確認したカード番号に書き換えてください。

6)プログラムを実行します。
sudo python3 TextToSpeech_Jtalk.py
・こんにちはと女性の声で聞こえたら完成です。
※先ほど説明しましたが、再生時にスピーカーのカード番号/デバイス番号の指定を間違えないようにしましょう。間違えると再生がエラーとなります。