1)Googleのライブラリー(Google Cloud Speech API)を利用して、録音した音声を文字データに変換するプログラムを作成します。
①必要なライブラリをインストールします。
Googleのライブラリー
sudo pip3 install –upgrade google-cloud-speech
※upgradeの前のハイフンは2つです。
音声データを取り扱うライブラリー
sudo apt-get install alsa-utils sox libsox-fmt-all
➂Googleの環境準備で作成したキーをPython3のフォルダーにコピーします。録音した音声データ「voice.wav」も合わせて用意します(前章で何か録音したデータをそのまま利用します。)。
④プログラムを記述します。[VoiceToText_Google.py]
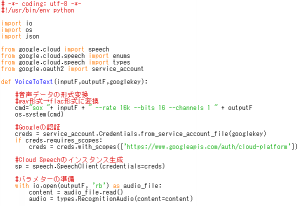

⑤前章で取得したサービスキー名(json形式のファイル名)を入力し、プログラムを実行します。
sudo python3 VoiceToText_Google.py

※文字化したデータとその確度が表示されたらOKです。