1)目的
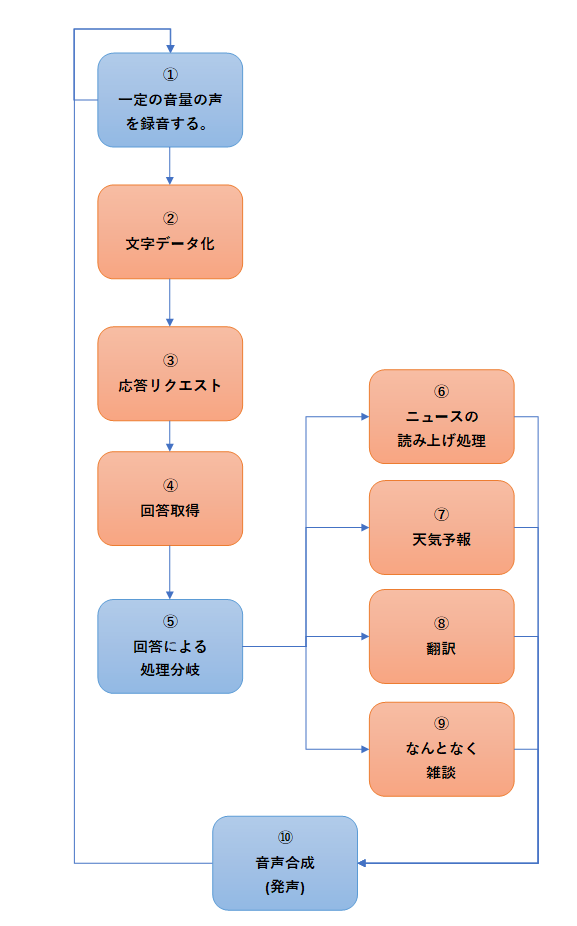
ロボットとのコミュニケーションをとるために、まずは人が話したことを聞き取る必要があります。そのための音声の録音機能を用意します。
録音した音声データはwav形式の音声データとして保存します。
2)用意するもの
マイク
スピーカー
※ともに、USB接続のもので安価なものを用意します。
3)開発手順
①準備
マイク、スピーカーをRaspberry Piに接続します。
➁マイクの優先度の確認と設定
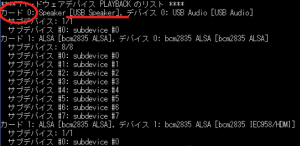
terminalを起動し、下記のコマンドで接続したマイクの優先度を確認します。
cat /proc/asound/modules ←マイクの優先度を確認するコマンド

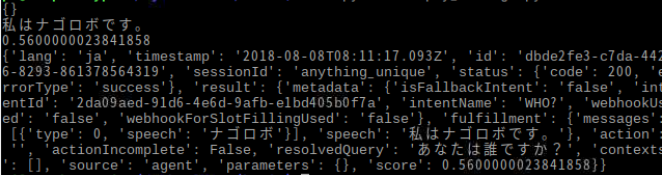
snd_usb_audioがUSB接続となることから、USB接続の優先度を上げる設定を行います。上記の図では現在優先度が1なので0に優先度を上げます。0から順にマイクの優先順位が決まります。
下記のコマンドで設定ファイルを編集します。存在しない場合は新規に作成します。設定ファイルを作成する場合にも下記のコマンドで作成/編集する事ができます。
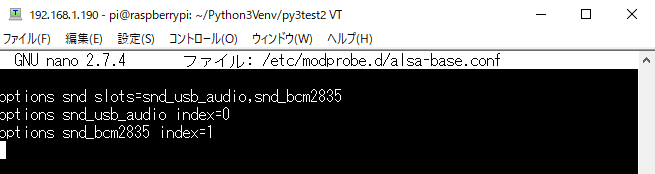
sudo nano /etc/modprobe.d/alsa-base.conf
下記の設定を記述します。(存在しない場合は同じ内容を入力してください。)
options snd slots=snd_usb_audio,snd_bcm2835
options snd_usb_audio index=0
options snd_bcm2835 index=1
 保存したら、記述が反映されているか確認します。
保存したら、記述が反映されているか確認します。
sudo cat /etc/modprobe.d/alsa-base.conf

確認出来たら、Raspberry Piを再起動します。
再起動後、再度マイクの優先度を確認します。
cat /proc/asound/modules

snd_usb_audioの優先度が上がっていることを確認します。
➂ライブラリとしては以下のコマンドでインストールします
sudo apt-get install portaudio19-dev ←今回利用するライブラリ関連
sudo pip3 install pyaudio ←今回利用するライブラリ
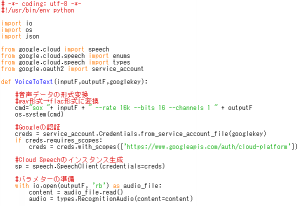
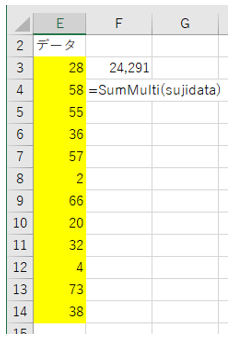
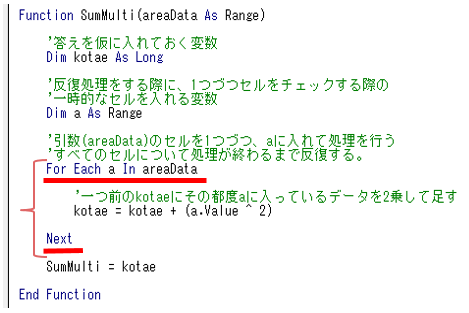
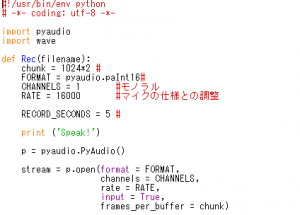
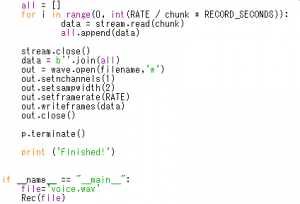
④録音用のシンプルなプログラムを記述して、実行します。
[ファイル名]Rec_Voice.py
[プログラム]
⑤プログラムの実行
プログラムの実行は下記のコマンドで実行してください。
sudo python3 Rec_Voice.py
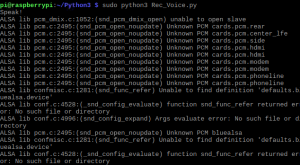
プログラムを実行しマイクに話しかけてください。
プログラム終了後、Python3のフォルダーに下記の音声ファイルが保存できていれば、成功です。
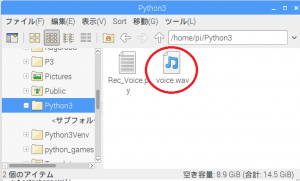
うまく録音できると、フォルダプログラムを実行したフォルダ内にvoice.wavというファイルができるので下記のコマンドで再生してみましょう。録音ができていれば完成です。
aplay voice.wav ←音声を再生するコマンド aplay 音声ファイル
上記のコマンドで再生できない場合、スピーカーのカード番号を確認してください。
aplay -l ←スピーカーのカード番号を確認するコマンド
USB Speakerのカード番号を確認します。下記の図を見るとカード番号が2番になっています。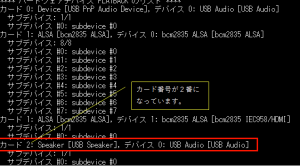 音声を再生するコマンドに今度はカード番号を指定して再生してみてください。
音声を再生するコマンドに今度はカード番号を指定して再生してみてください。
aplay -D plughw:2 voice.wav ←カード番号を指定し再生するコマンド
aplay -D plughw:[カード番号] [音声ファイル]でカード番号を指定し、再生する事ができます。
録音は以上です。
※録音にあたってのパラメータは設定が難しいので、細かく理解するというよりはとりあえず、録音できればOKとして先に進みましょう。
※マイクの感度が悪い場合には以下のコマンドでマイクの確認を行い、感度を調整しましょう。
下記のコマンドで、マイクデバイスのカード番号を確認しましょう。
arecord -l

カード番号が0番ということが確認できます。
次に0番のマイクの設定状況を以下のコマンドで確認します。
amixer sget Mic -c 0

音量が0-62の範囲で、最大の62であることがわかります。この数値を6~7割くらいに設定しておきましょう。
下記のコマンドで45/62で設定をします。
amixer sset Mic 45 -c 0

前の投稿/次の投稿/メニューページへ戻る