1)Raspberry Pi
ロボットの頭脳となるのはコンピュータですが、今回利用するのは通常利用しているようなパソコンではなく、Raspberry Piという手のひらに載るような小さなコンピュータを利用します。
Raspberry Piにもいくつか種類がありますが、その中でも安価で最も小さいRaspberry Pi ZeroかRaspberry Pi 3(Zeroよりは金額が少し高いです。)を使います。Zeroより3の方が性能が良く、今後プログラムを作成していく中でZeroでは未対応の物なども出てきます。

2)用意したもの
①Raspberry Pi Zero WH (GPIOをあらかじめ半田付けした製品)もしくはRaspberryPi3(写真はzeroです。)
②microSDカード 8G (R-20M/W-14M) (フォーマット済み)
③USB変換アダプター
④HDMI変換アダプター
⑤USB電源アダプター
⑥マウスとキーボード(写真にはありません。)
⑦モニタとHDMIケーブル(写真にはありません。)
⑧各種作業を行うためのPC(パソコン)
⑨USBマイク(写真にはありません)
⑩USBスピーカー(写真にはありません)
⑪USBハブ
⑫HDMI-VGA変換アダプタ


3)環境を作るためにすること
まずは、普通のパソコンのように利用できるようにすることを目標とします。その環境を作るために行うことは以下の通りとなります。
①OSイメージファイルのダウンロード
➁OSイメージファイルを展開するツールのダウンロードとインストール
③OSイメージファイルの展開とmicroSDカードへの書き込み
④Raspberry Pi の起動
⑤日本語の設定
⑥wifiの設定とブラウザ起動の確認
⑦日本語入力の設定
⑧パスワードの変更
では、順番に行っていきましょう。
①OSイメージファイルのダウンロード
最初は手元のPCで準備をします。
「Raspberry Pi」以下のサイトからOSのイメージ(ファイル)をPCにダウンロードする。ダウンロード対象は「RASPBIAN STRETCH WITH DESKTOPのDownload zip」を選択してください。
https://www.raspberrypi.org/downloads/raspbian/
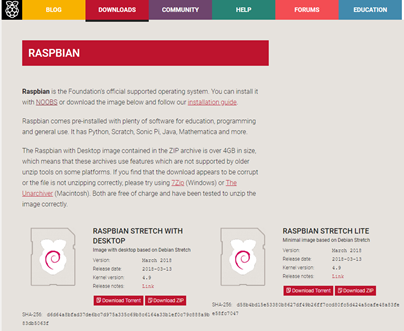
※こんな感じのファイルがダウンロードされます。「2018-03-13-raspbian-stretch.zip」
➁OSイメージファイルを展開するツールのダウンロードとインストール
「Resin.io」の以下のサイトから、OSのイメージを展開して、microSDカードに書き込むためのツール「Etcher」をダウンロードし、PCにインストールする。ダウンロードは、下図の赤枠の中の部分からできます。
https://etcher.io/
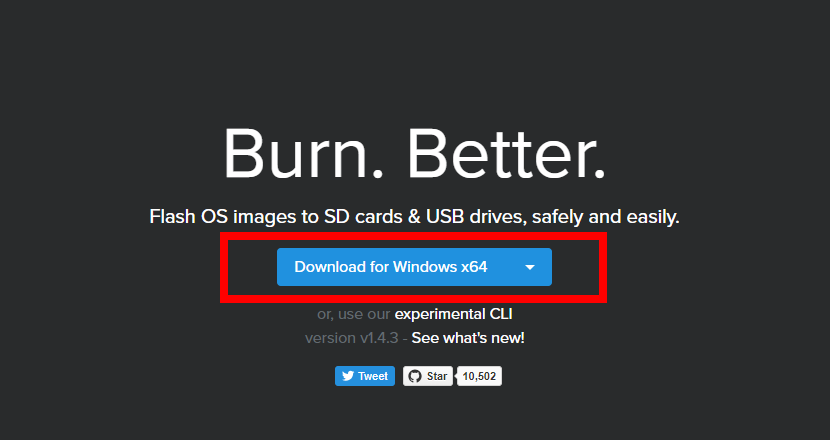
※こんな感じのファイルがダウンロードされます。「Etcher-Setup-1.3.1-x64.exe」
ダウンロードされたファイルをダブルクリックして下さい。インストールが開始されます。基本的にはデフォルトのままインストールしてもらえれば問題ありません。
➂OSイメージファイルの展開とmicroSDカードへの書き込み
PCにmicroSDカードを接続してください。新規に購入したものであればそのまま利用できます。もし、再利用する場合にはフォーマットしてから利用してください。
PCにmicroSDカードを直接接続できない場合にはアダプターを利用してください。
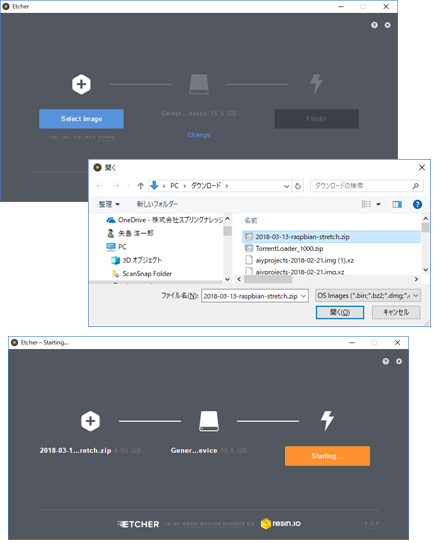
接続したら、Etcherを起動し、「Select image」をクリックして、先程ダウンロードしたOSイメージファイルを選択してください。
選択したら「Flash」をクリックしてください。この操作で展開とmicroSDカードに自動的に書き込みされます。(少し時間がかかります。)
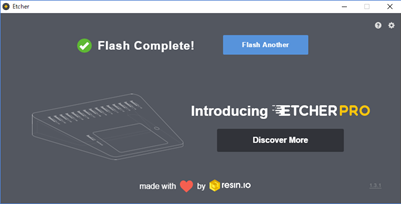
完了すると以下の画面が表示されます。表示されたらmicroSDカードを取り出してください。
④Raspberry Pi の起動(起動方法はZeroも3も同じです。)
いよいよ、ここからはRaspberry Piを使った作業となります。
・microSDカードの差し込み(接続)
・モニタの接続
・キーボード/マウスの接続
・電源ケーブルの接続
を順番に行ってください。
すべて接続が完了した後に、電源ケーブルをコンセントに差し込んでRaspberry Piを起動します。(コンセントにさすと自動的に起動します。起動スイッチのようなものはありません。)画像のように電源ケーブルは端に差すようにしてください。
モニタに下記のような画面が表示されると起動できたことになります。

⑤日本語の設定
起動したOSの画面は英語表記となっていることから、環境を日本語に変更します。
いちごのマークをクリックしてメニューを表示「Preference」「Raspberry Pi Configuration」を選択して設定画面を表示します。
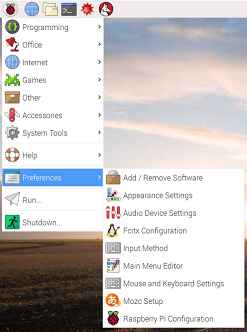
画面が表示されたら
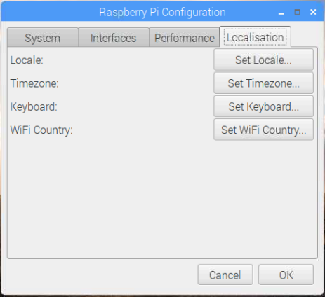
[Location]のタブを選択して、「Set Locale」「Set TimeZone」「St Keyboard」「Set WiFi Country」を順番に日本(Japan)もしくは日本語(Japanese)に設定を変更してください。変更後、設定画面のOKボタンをクリックすると再起動を促されるので、再起動させると表示が日本語に変更されます。メニューが日本語になっていることを確認してください。
⑥wifiの設定とブラウザ起動の確認
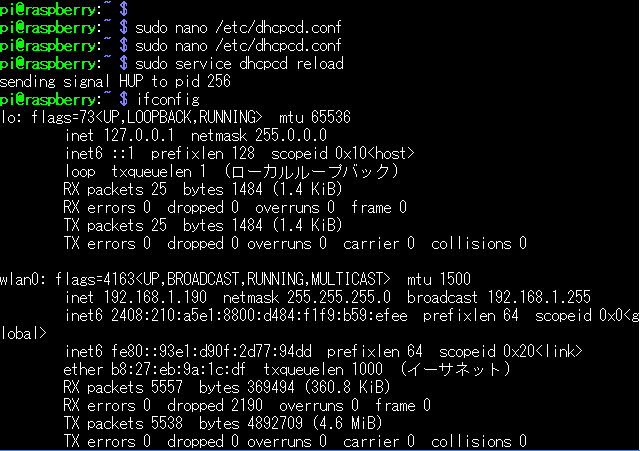
インターネットに接続するためにネットワークに接続します。RaspberryPiZeroには有線LANの接続口がないためWiFiで接続します。
右上の のマークをクリックすると接続可能なWiFiのリストが表示されます。接続するWiFiを選択するとキーの入力を促されるのでキーを入力して接続してください。
のマークをクリックすると接続可能なWiFiのリストが表示されます。接続するWiFiを選択するとキーの入力を促されるのでキーを入力して接続してください。
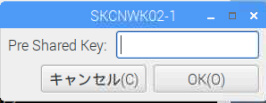
接続後は右上のマークが となっていることを確認したうえで、左上の
となっていることを確認したうえで、左上の をクリックしてブラウザを起動。何かしらのページを表示してインターネットに接続できていることを確認してください。
をクリックしてブラウザを起動。何かしらのページを表示してインターネットに接続できていることを確認してください。
※RaspberryPiZeroはコンピューターとしては画像処理をスムーズに行えるほどの能力を持っていないことからブラウザの表示を含めて時間がかかることが想定されます。
⑦日本語入力の設定
RaspberryPiでは表示が日本語でなかったのと同様に、入力についても日本語の設定が必要となります。(設定しない状態では日本語の入力はできません。)
左上の「Terminal」を起動します。
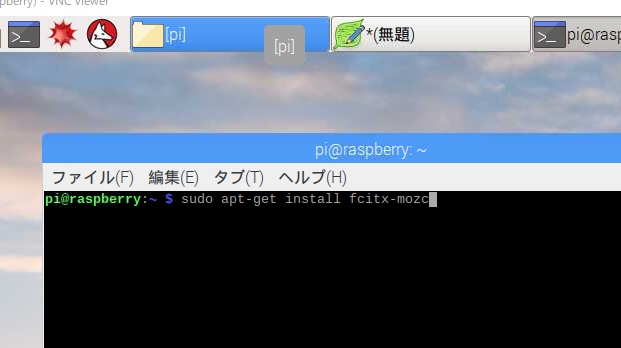
起動したら以下のコマンドを入力し、Enterキーを押してください。
sudo apt-get install fcitx-mozc
コマンド入力後、インストールの続行確認が出てきますので、yキーを押して続行してください。
そうすると日本語入力のために必要なアプリケーションやライブラリなどがインストールされます。(しばらく時間がかかります。)
インストールが完了したら、念のため再起動してください。
【再起動の方法】
左上の マークをクリックするとメニューが表示されます。メニューから「Shutdown」をクリックします。クリックすると「Shutdown options」というメニューが表示されるので、2段目の「Reboot」を選択すると再起動できます。
マークをクリックするとメニューが表示されます。メニューから「Shutdown」をクリックします。クリックすると「Shutdown options」というメニューが表示されるので、2段目の「Reboot」を選択すると再起動できます。
再起動後、メニューから、「アクセサリ」「TextEditor」を起動してください。
起動したTextEditorを選択(アクティブ)にした状態で、右上の をクリックすると
をクリックすると に変わります。この状態で入力すると日本語が入力可能となります。
に変わります。この状態で入力すると日本語が入力可能となります。
⑧パスワードの変更
Raspberry Piはデフォルトの設定で、デフォルトのユーザーID及びパスワードで起動時に自動的にログインして起動します。その際のユーザーIDとパスワードは
ID pi / パスワード raspberry
となります。新しいIDを作成するかは別として一応パスワードは変更しておきます。
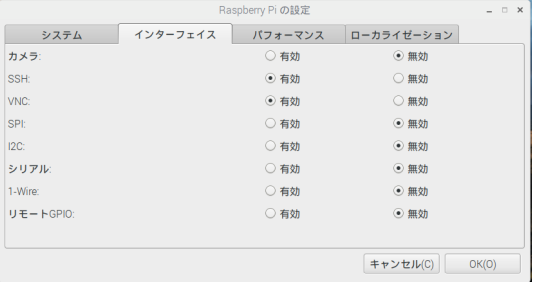
メニューからをクリック、「設定」「Raspberry Pi の設定」を選択し、設定画面を起動します。「システム」タブを選択して、「パスワードを変更(P)」をクリックすると新しいパスワードを変更する画面が起動します。新しいパスワードを入力して更新してください。
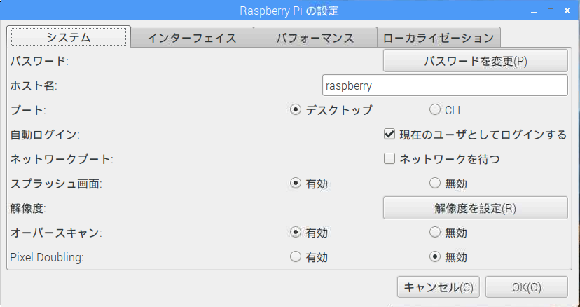
同じタブで、「自動ログイン」にチェックがついている場合には、自動的にログインして画面が起動することから変更しても特にわかりません。いったんこのチェックを外して再起動しパスワードが変更できていることを確認してください。
【HDMIの有効化】
シャットダウンの前にconfig.txtのHDMIを有効にしましょう。ラズベリーパイの設定を行ったあと、シャットダウンを行うとHDMIが有効になっておらず、モニターに画面が表示されない事があります。次回、起動時にモニター上で画面が確認できるようにconfig.txtのHDMIを有効にしてからシャットダウンしましょう。
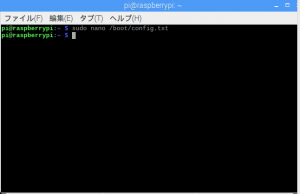
①terminalを起動
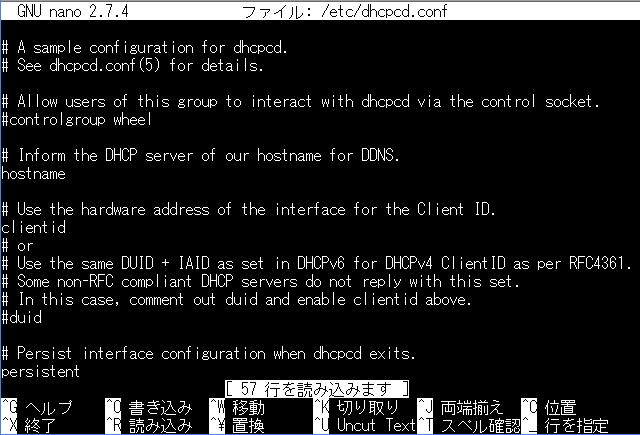
②sudo nano /boot/config.txt ←config.txtを編集するためのコマンド
③下記の赤線部分の#を削除。
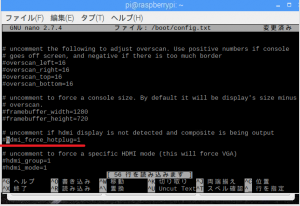

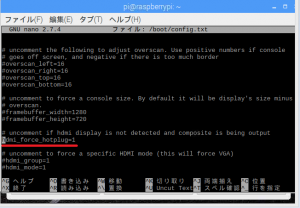
④Ctrl+Oで上書き保存し、Ctrl+Xでconfig.txtを閉じてください。念のために再起動を行いましょう。
【シャットダウンの方法】
左上のマークをクリックするとメニューが表示されます。メニューから「Shutdown」をクリックします。クリックすると「Shutdown options」というメニューが表示されるので、1段目の「Shutdown」を選択するとシャットダウンできます。
以上でRaspberry Piの環境設定は終了です。一応パソコンと同じように利用できるようになりました。
※Raspberry PiのOS設定画面の起動。
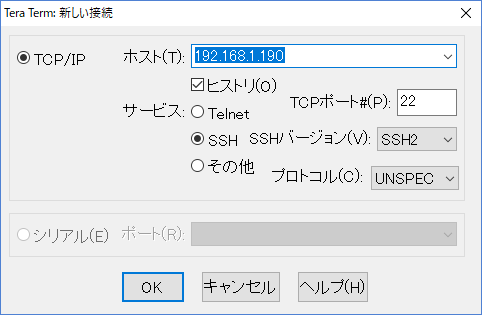
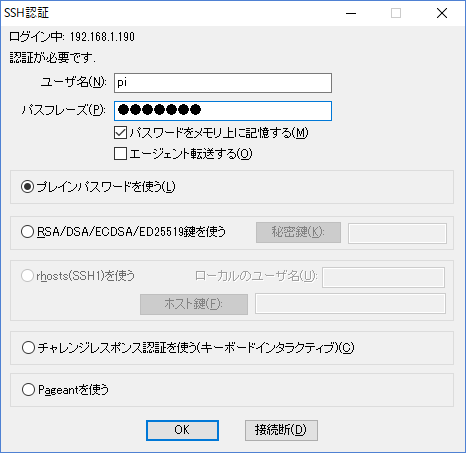
Terminalを起動し、下記のコマンドで設定画面を起動します。
sudo raspi-config
次の投稿/メニューページに戻る

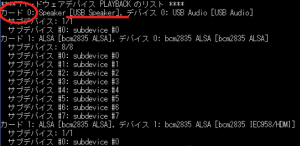


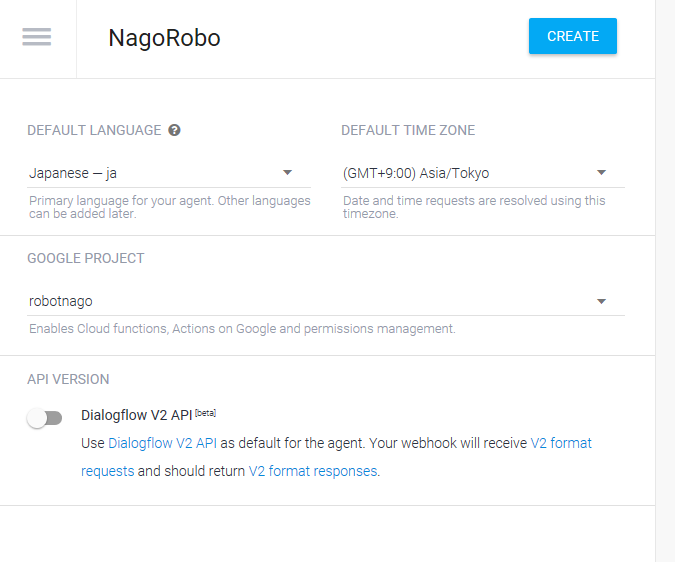
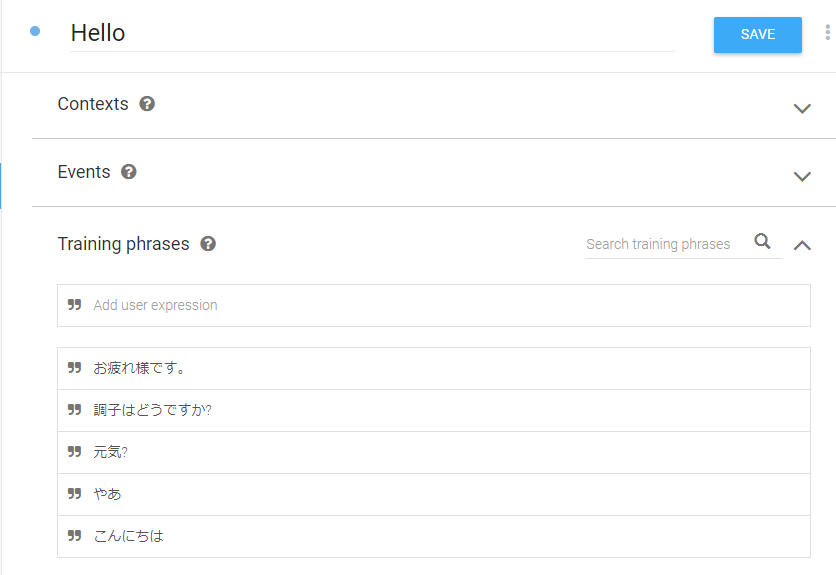
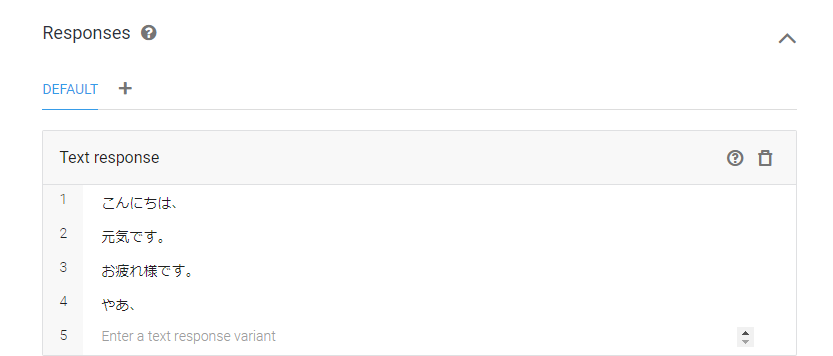
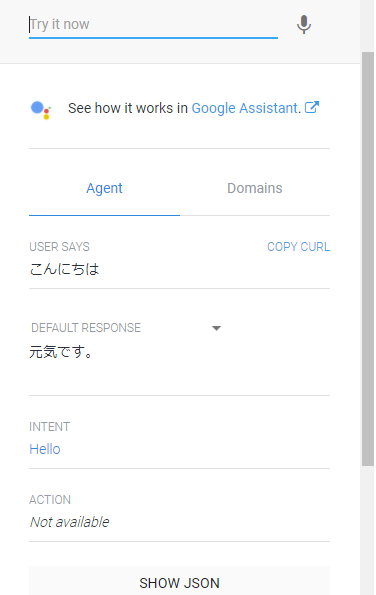
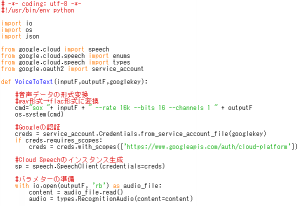




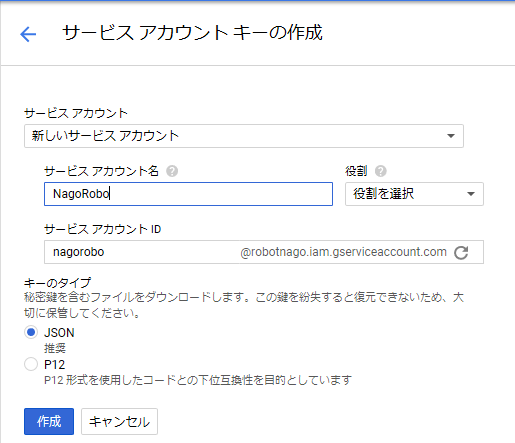


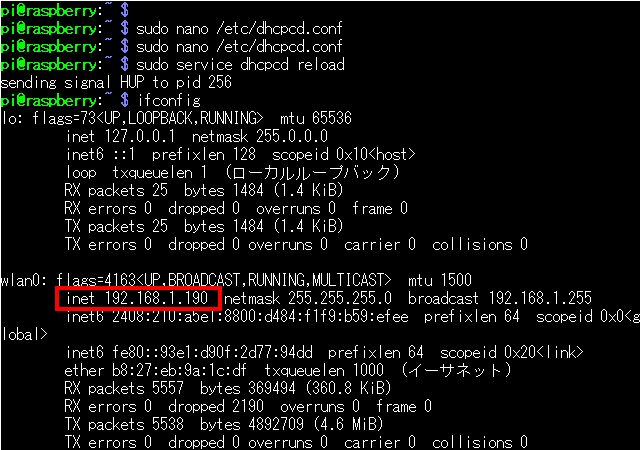
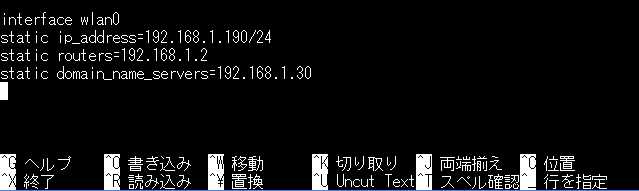
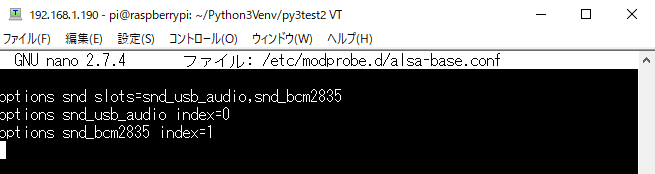 保存したら、記述が反映されているか確認します。
保存したら、記述が反映されているか確認します。

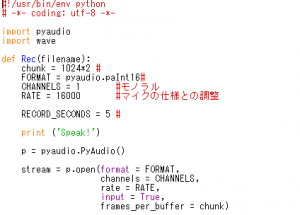
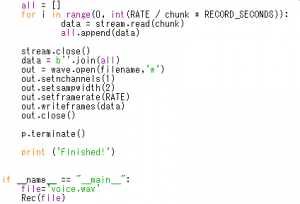
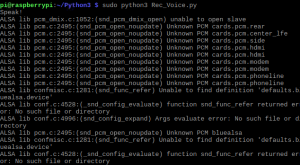
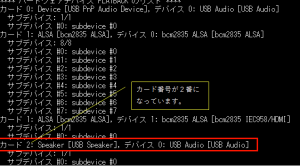 音声を再生するコマンドに今度はカード番号を指定して再生してみてください。
音声を再生するコマンドに今度はカード番号を指定して再生してみてください。